Nginxを用いたWebSocketサーバのReverseProxy構成及びSSL/TLS接続
TL;DR
今更ながら、随分前の作業メモが貯まっていたのと、もう一つの記事のつなぎとするために吐き出しておく。
WebSocket 通信のSSL/TLS通信をさせたりロードバランシングさせたい場合など、WebSocketサーバの前段にReverseProxyを置きたい時は Nginx (v1.3.13 以降) を使おうという話。
なお、AWSのELB (ALB: Application Load Balancer) を使っても実現できるようになったので、AWSで運用しているサービスの場合はALB使ったほうがお手軽省コストメリット大きいと思う。
はじめに
以前Node.js 自身でSSL/TLS通信する方法を記したが、 シングルコアで動作するNode.jsプロセスに、暗号化のオーバーヘッドまで食わせるのは非常にもったいない。 pm2などのNode.js製のクラスタリングツールでマルチプロセス化はできるとはいえ、Node.jsサーバのコンピューティングリソースは本来の責務であるアプリケーションロジックに集中させたい。
Nginx v1.3.13以降 のWebSocket Support
WebSocket接続のハンドシェイク時、HTTP/1.1 101 (Switching Procotols) というステータスコードとHop-by-Hopヘッダを使用してWebSocket通信への切り替えを行う。
2013年02月にリリースされたNginx v1.3.13 で、これらの仕様に対応された。
WebSocket proxying - http://nginx.org/
Since version 1.3.13, nginx implements special mode of operation that allows setting up a tunnel between a client and proxied server if the proxied server returned a response with the code 101 (Switching Protocols), and the client asked for a protocol switch via the "Upgrade" header in a request.
これをReverseProxyとして挟む。
Try it!
ということで試してみる。
Install Nginx
まずはインストール。
NginxのRepositoryを登録し、Nginxをインストールする。 Nginx 1.3.13以降であれば良いので、Latest versionをインストールする。
Ansible Playbookのサンプルを載せておく。
Nginx Configuration
設定方法は公式ドキュメントにあるとおり。
WebSocketのハンドシェイク時に使われる Upgrade ヘッダと Connection ヘッダ は Hop-by-Hop ヘッダ である。 通常のEnd-to-End headerと異なり基本的に一度の転送に対して有効なヘッダなため、ReverseProxyを間に挟んでいる場合これらのheaderはバックエンドサーバまで届かない。
以下、Hop-by-Hop ヘッダに関するRFCのリンク。
RFC 2616 - Hypertext Transfer Protocol -- HTTP/1.1
以下、Nginxのリンク。
WebSocket proxying - http://nginx.org/
As noted above, hop-by-hop headers including "Upgrade" and "Connection" are not passed from a client to proxied server, therefore in order for the proxied server to know about the client's intention to switch a protocol to WebSocket, these headers have to be passed explicitly:
Nginxも例外ではないため、WebSocket通信をプロキシする場合は明示的にこれらのヘッダをバックエンドに渡すようにする必要がある。
この設定を入れて、Nginxを起動する。
$ sudo systemctl start nginx.service
なお、後段のNode.jsサーバは、以前使ったサンプルアプリケーションを再利用する。
server
package.json
client
How to run
$ vim app.js $ vim package.json $ vim /usr/share/nginx/html/sample.html $ npm install $ node app.js
動作確認
ブラウザで動作確認してみる。複数のタブで sample.html を開いてそれぞれで投稿したコメントが同期できればOK。

画像左部のDeveloper Toolsでも分かる通り、101 (Switching Protocols) が通り、WebSocket接続が確立できていることが分かる。
Request / Response Headerは以下。Hop-by-Hopヘッダも期待通りセットされている。
Request URL
ws://your.domain.or.ip/socket.io/?EIO=3&transport=websocket&sid=3_K8sGX3W6bYyXAAAAAe
Request Headers
Accept-Encoding : gzip, deflate, sdch Accept-Language : ja,en-US;q=0.8,en;q=0.6 Connection : Upgrade Cookie : io=lsIxmwKy6QY8s9ocAAAQ Host : (your domain or IP) Origin : http://your.domain.or.ip Sec-WebSocket-Extensions : permessage-deflate; client_max_window_bits Sec-WebSocket-Key : aZWrWEnJQsBvp38sAtBP1A== Sec-WebSocket-Version : 13 Upgrade : websocket
Response Headers
Connection : upgrade Date : Mon, 19 Sep 2016 07:30:43 GMT Sec-WebSocket-Accept : 9wz2i4UrQXQqilnyAtByxzwbwb8= Sec-WebSocket-Extensions : permessage-deflate Server : nginx/1.10.1 Upgrade : websocket
WebSocket通信を暗号化する
SSL/TLS Termination
あとは、このNginx Reverse Proxy - cient間の通信を暗号化すれば良い。 普通に、サーバ証明書 + 中間CA証明書 と 秘密鍵を配置して ssl on; すれば良いだけ。
Nginx を再起動して、https で sample.html を開き直せばws通信もSSL/TLS化される。
Request URL
wss://your.domain.or.ip/socket.io/?EIO=3&transport=websocket&sid=uLFmikk0IVrjBy8bAAAb
非常に簡単。
HTTP/HTTPSとWebSocket (ws/wss) の両接続を単一のNginxで終端する
上述の Nginx の設定ファイルを見て分かる通り、locationを分けることで単一のNginx かつ同じ 443 portで、通常のHTTP/HTTPSとWebSocket (ws/wss) の両通信を扱うことが出来る。 今回のように両要件を共存で動かす場合や、一つのNginx Reverse Proxy クラスタ、同一ドメインでサービス提供する時などに活用できると思う。
※ステートレスな通信であるHTTP/HTTPSと違い、WebSocketは接続を持続するステートフルな通信となるので、リソースには要注意。
まとめ
Reverse Proxyを挟んでおくと色々と小回りが効き運用上も楽になることが多いので、前記事のように対応するよりもこちらの方がベターだと思う。 餅は餅屋。
ちなみに、2016年8月にAWSのElastic Load Balancerが WebSocketに対応した。ALB (Application Load Balancer) というらしい。 ELBのラインナップに含まれる形で、以前のELBは "Classic" という扱いとなるらしい。
また別に書くが、スムーズすぎて心配になるくらい簡単に導入できるので、AWSで運用している方はALBを使ったほうがメリット大きいと思う。 お手軽で省コスト。
")
- 作者: 久保達彦,道井俊介
- 出版社/メーカー: 技術評論社
- 発売日: 2016/01/16
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (4件) を見る
OS boot/shutdown時に自動でZabbixのホストのステータスを変更する
tl;dr
OS 起動・停止時にZabbixのホストのステータスの有効・無効を切り替えるサンプルプログラムを書いた。
uorat/zabbix-host-controller - Github
前置き
クラウドを使うことのメリットの一つに、リードタイムなくサーバの稼働数を柔軟に制御できる点がある。 例えばAWSの場合、AutoScalingを使ってシステム負荷などに応じてサーバを動的に生成・削除できる。 AutoScalingが要件にあわなければ、あらかじめ作成しておいたEC2に対してAPIでサーバの起動/停止を制御できる。
必要なリソースを必要なタイミングで調達し稼働させることでコストメリットを受けられるし、システムキャパシティを拡げ可用性を上げることができる。
ただ、運用まで見据えると、考慮しておくべきことが幾つか出てくる。 その一つが監視で、動的なサーバの増減、up/downに対して監視をどのように追従させるかがポイントとなる。
増えたものは監視したいし、スケールインしたことにより正常に止まった・消えたものは監視を止めて良い。 検証環境も、営業時間内は監視しておきたいし営業時間外は止めるから監視したくない。 ただし、スケールインしていないにもかかわらず疎通不可になっただとか、プロセス障害だとか、そうした異常なステータスは検知したい。
今回のお題
サーバの稼働数をアプリケーション側で制御するようなシステムがある。 この監視 (Zabbix) の有効・無効を自動で切り替えてみる。 イメージはこちら。

アプローチ
ZabbixはAPIが提供されている。
17. API - Zabbix Documentation 2.4
host.get や host.create, host.update などホストの情報を参照したり、作成・更新できるので、これを活用すれば良い。
※Zabbixの 「メンテナンス」機能は、計画的な起動・停止でないと使いづらいことと、設定後対象のホストが実際にメンテナンスになるまで数十秒程度のタイムラグが発生することから、要件にマッチしないので今回は扱わない。
監視の有効・無効のタイミングは、以下の決めとする。
- OS boot時: 監視を有効化
- OS shutdown時: 監視を無効化
kernel panicを起こしたり、プロセス障害が発生したり、突如疎通不可になった場合は検知するが、shutdownが走った時は正常停止とみなし監視を無効化する。 つまり、runlevelに応じて監視を制御できるようにする。
実装
Zabbi APIは仕様が非常にシンプルなので、サードパーティのラッパーは使用せずにそのまま直で実装する。 Zabbix API は以下のような仕組みとなる。
- user.login で auth ID
- auth ID を使って後続のAPIを実行
軽く書いてみた。ソースは以下。 (CentOS6 / AmazonLinux 動作確認済み)
uorat/zabbix-host-controller - Github
スクリプトは単純明快なので中身の細かい説明は割愛するが、 zabbix_module.py の中で loginやhostidの取得、ステータスの更新を行う関数を定義してあり、 zabbix_enable.py と zabbix_disable.py でこれらの関数を呼び出している。 bin/zabbix_config.py 内にZabbixの接続情報を定義できるようにしてあるので、環境にあわせて変更する。
あとは、起動スクリプトでこれらのスクリプトを実行するようにして、chkconfigでサービス登録すれば良い。 起動スクリプトは example/zabbix-host-controller.init を使えば基本的にそのまま動くはず。 これで、サーバが立ち上がるとZabbixのホストステータスが有効になり、シャットダウンすれば自動で無効化される。
手動実行するとこんな形。
$ /etc/init.d/zabbix-host-controller start => host: your-host01, hostid: 11407, status: 1 => status update : hostid: 11407, result: True => host: your-host01, hostid: 11407, status: 0 zabbix-host-control start: [OK]
$ /etc/init.d/zabbix-host-controller stop => host: your-host01, hostid: 11407, status: 0 => status update : hostid: 11407, result: True => host: your-host01, hostid: 11407, status: 1 zabbix-host-control stop: [OK]
まとめ
割とシンプルに実現できるので、お試しあれ。 上記のコードは、既にZabbixに登録されているホストの有効/無効しかできないので、 気が向いたら初期登録やテンプレートの設定、スクリーンへの追加なども対応させて、AutoScalingに追従できるようにするかも。
")
改訂版 Zabbix統合監視実践入門 ~障害通知、傾向分析、可視化による省力運用 (Software Design plus)
- 作者: 寺島広大
- 出版社/メーカー: 技術評論社
- 発売日: 2014/06/17
- メディア: 大型本
- この商品を含むブログ (1件) を見る
")
Zabbix統合監視徹底活用 ~複雑化・大規模化するインフラの一元管理 (Software Design plus)
- 作者: TIS株式会社,池田大輔
- 出版社/メーカー: 技術評論社
- 発売日: 2014/02/07
- メディア: 大型本
- この商品を含むブログ (4件) を見る
HLS動画の配信テスト用に、JMeterで同時視聴シナリオを書いてみた
RTMP サーバ から AkamaiやCloudFrontのようなCDN 経由で HLSによるライブ配信を行っているとする。 構成は、以下のようなものを想像してもらえれば良い。

同時視聴者数の増加に従ってOriginにどのような負荷がかかるのか確認したかったので、シナリオを組んでみた。
前提: HLSのおさらい
HLS (HTTP Live Streaming) はAppleが開発した仕様。動画を10秒など適度な長さでセグメント化し、セグメントファイルの場所や再生時間、再生順序などが記録されたプレイリストに従って再生するもの。bitrate毎のプレイリストを用意することでAdaptive Bitrateにも対応できる。
詳しくはこのあたりにまとまっている。
- HTTP Live Streaming (HLS) - Apple Developer
- HTTP Live Streaming Overview - iOS Developer Library
- draft-pantos-http-live-streaming-19 - HTTP Live Streaming
- 動画配信技術 その1 - HTTP Live Streaming(HLS) - Akamai Japan Blog
背景: ライブ配信は同一ファイルへのリクエストが集中する
VODのHLS配信であれば既に動画の長さは決まっているので、セグメントファイル (*.ts) とプレイリスト (*.m3u8) がCDNのキャッシュに乗るようにCache-Controlを調整してあげれば良い。CDNのキャッシュに乗りさえすれば、あとはClientとCDN の Edgeの世界に閉じるので、Cache Hit率さえ気をつけておけば、Originの負荷はさほど気にする必要はない。
ただし、ライブ配信の場合はセグメントファイルは常に生成され、プレイリストも常に更新される。CDNに古いプレイリストがCacheされてしまうと動画視聴に支障が出るので、TTLはsegment-timeにあわせて短くする必要がある。 また、ロングテールなVODコンテンツと異なりライブ配信の場合、多数のユーザが同時に同じセグメントファイルとプレイリストを参照することになる。Cacheに乗っていなければ、当然Originにリクエストが流れる。
そのため、同時視聴者数の増加に従ってOriginにどのような負荷がかかるのか確認したかったので、シナリオを組んでみた。
HLS視聴のシナリオ作りの勘所
前置きが長くなったが本題。
プレイリストの定期取得とプレイリストに従ったセグメントファイルの取得を模倣する必要がある。ざっと流れは以下。
- playlist.m3u8
- (loop start)
- chunklist_${bitrate}.m3u8
- media-${chunk}.ts
- wait for segment-time
- (loop end)
今回はJMeterクラスタがちょうど手頃に使える環境にあったので、この流れに沿ってHLS視聴のシナリオを組んでみた。 XMLは記事末のGist参照。
全体像は以下のような感じ。

一つずつ説明する。
0. 初期値を設定
Test Planのユーザ定義変数を使ってドメインやポート、Pathやセグメントファイル長など環境や配信毎に変わりうる値を変数化しておく。

また、HTTPリクエスト初期値を定義し、後続のサンプラで冗長な設定をせずに済むようにしておく。

あとは、HTTP Header Manager や HTTP Cache Manager を環境やシナリオにあわせて定義する。 自分は、主要ブラウザにあわせてGzip圧縮前提で試験したかったので、Request Header に "Accept-Encoding: gzip" を入れるようにした。
1. Master Index fileを取得
初期値で定義したURLに対してHTTP Requestを送信するだけで、ここはシンプル。

Bandwidthとbitrate毎のプレイリストが手に入るので、正規表現を HTTP Request Sampler の後に追加して必要なプレイリストを抽出し、変数に格納しておく。

2. (以下繰り返し) Playlistを取得
ライブ配信の場合、プレイリストやセグメントファイルが定期的に更新/追加されるため、以降繰り返し処理となる。
1. で取得したプレイリストのファイル名をもとに、プレイリストを取得する。

セグメントファイルの一覧が手に入るので、1. と同じ要領で正規表現でセグメントファイル名を抽出し、変数に格納しておく。

3. セグメントファイルを取得する
- で取得したセグメントファイルのPathをもとに、セグメントファイルを取得する。ここもシンプル。

4. wait
以降、2と3の繰り返しになるが、マニフェストファイルはセグメントファイルの長さ程度の頻度でfetchするため、2の処理に入る前にWaitさせるようにする。

以上がシナリオ。 動かした時のアニメーションGIFを載せておく。

あとはThread数やThread Groupを増やしたり、複数のJMeterにリモート実行するなりして、多重度増やして試験すれば良い。 JMeterのリモート実行方法は、以下を参考にすればすんなり出来ると思う。
- Mac の JMeter クライアントから EC2 環境の JMeter サーバを使って負荷試験を行う - my scratch pad
- SpotInstanceとJMeterを使って400万req/minの負荷試験を行う | Developers.IO
最後に
参考までに、私の環境での結果の概要を載せておく。 使っている製品や環境、セグメントファイル長、画質など様々な要因で性能や傾向はかなり変わると思うので、あくまで参考までに。 試験内容や結果に突っ込みあればコメントください。
環境
- CDN: CloudFront
- Origin: Wowza Streaming Engine 4 on EC2 (g2.2xlarge)
- 配信設定: H.264, bitrate 2500 (CBR), キーフレーム2秒
- セグメントファイル長: 2秒
- Cache-Control
- プレイリストファイル max-age = 1
- セグメントファイル max-age = 3600
傾向
- セグメント長が2秒と短く、Cache-Control も max-age = 1 のような短いものとしても、多重度を上げるとちゃんとCache Hitしてくれた
- 多重度を10,000程度まであげて試験してみたが、Originサーバには大した負荷はかからなかった。
- 同時視聴者数が数千レベルまで増えると、CDN - Origin server間のTCP Connection数が微増した程度。
- CPUやメモリ、Network IOも大したレベルではなかったので、CDNの恩恵にあずかれた。
- プレイリストファイルへのリクエストをOriginに全てPassする設定を加えたところ、CDN - Origin server間のTCP Connection数がリニアに増え、Originの負荷も増となった。
- まぁ当然だよね。Bad knowhow。
1 RTMPサーバ + CloudFrontを挟む程度で、数千人程度のライブ配信はで捌けてしまいそう。
Originの可用性など考えると、RTMPサーバをさらにOriginとEdgeで分離する以下のような構成にしたほうが良いとは思う。
 その分サーバ稼働費やライセンスなどかかるので、このあたりは費用対効果考えて、判断すれば良いと思う。
その分サーバ稼働費やライセンスなどかかるので、このあたりは費用対効果考えて、判断すれば良いと思う。
Gist
HAProxy v1.6を使って複数のRDS Read Replilcaに分散させる
RDS ReadReplicaを立てて、参照クエリを逃がすことを考える。 可用性や拡張性を考えてReadReplicaは複数台構成とした場合、RDSの仕様を考慮して設計しておく必要がある。ポイントは以下。
- Read Replicaは個々にEndpoint (DNS名) を持つ。
- 複数Read Replicaに対してバランシングする仕組みは提供していない。
- ELBは RDS (Read Replica含め) には使えない。ELBにぶら下げられるのはEC2のみ。
- Read Replica各ノードの死活監視、障害時の切り離し/切り戻しを考慮する必要がある。
ということで、Read Replicaのバランシングを行うなら、自分で仕組みを用意する必要がある。 実現方法はいくつか選択肢があるが、今回はL7のバランサーとして定評のあるHAProxyを使ってみる。
Architecture with HAProxy
ざっくりと、こんな感じ。
- 各WebサーバでHAProxyを稼働させる
- localhost で Listen する
- HAProxyのBackend serverはRead Replicaに向ける
- backupにMaster RDSを指定し、Read Replica全滅時はMasterに向ける
- 使い方
- 参照: localhost:3306 に接続。HAProxy 経由で Read Replica に接続する。
- 更新: RDS Master の Endpoint

HAProxyが複数Slaveへの振り分けと監視、Read Replica全滅時はMasterに向けるなど耐障害対策を担ってくれるので、アプリケーション側からは参照と更新のEndpointそれぞれ1つずつ記憶しておけば良い。
インストール方法
なお、HAProxy v1.5まではプロセス起動時にEndpointのA recordをキャッシュし、プロセス再起動するまで更新してくれないため、EndpointがDNS名であるAWS系のサービスとは相性が良くない。 (後述)
例えば、RDSのノード障害 ( →Failover) やインスタンスタイプ変更などによりEndpointのIPが変わった場合もHAProxyは古いIPを参照し続け、Backend serverのステータスがいつまで経ってもDOWNのまま変わらない。
2015年10月にリリースされたHAProxy v1.6から resolvers オプションが追加され、A record の変更を追従してくれるようになっているので、必ずv1.6以上を採用しよう。
What’s new in HAProxy 1.6 | HAProxy Technologies – Aloha Load Balancer
Server IP resolution using DNS at runtime In 1.5 and before, HAProxy performed DNS resolution when parsing configuration, in a synchronous mode and using the glibc (hence /etc/resolv.conf file). Now, HAProxy can perform DNS resolution at runtime, in an asynchronous way and update server IP on the fly. This is very convenient in environment like Docker or Amazon Web Service where server IPs can be changed at any time. Configuration example applied to docker. A dnsmasq is used as an interface between /etc/hosts file (where docker stores server IPs) and HAProxy:
なお、現時点でRPMは見当たらなかったので、要ソースコンパイル。 上述のとおり、各Web/APサーバにインストールするので、RPM化しておく。
RPMBuild HAProxy 1.6
検証実施したタイミングでは 1.6.4 が最新版だったので、これを利用した。 http://www.haproxy.org/download/1.6/src/haproxy-1.6.4.tar.gz
SPECファイルの詳細は割愛するが、CentOS 6 標準のYumで入るHAProxyの構成になるべく似せるようにした。 initスクリプトやlogrotateのサンプルファイル、haproxy.confのサンプル設置など。詳しくは文末のGist参照。
SPECさえ用意してしまえば、あとは rpmbuild するだけ。
$ su - rpmbuilder $ wget http://www.haproxy.org/download/1.6/src/haproxy-1.6.4.tar.gz $ tar xzvf haproxy-1.6.4.tar.gz $ vim ~/rpmbuild/SPECS/haproxy.spec (spec作成 & 必要なファイルの配置) $ tar zcf ~/rpmbuild/SOURCES/haproxy-1.6.4.tar.gz /haproxy-1.6.4 $ mv haproxy-1.6.4.tar.gz ~/rpmbuild/SOURCES/ $ cd ~/rpmbuild $ rpmbuild -ba SPECS/haproxy.spec $ ls -l ~/rpmbuild/RPMS/x86_64/ -rw-rw-r-- 1 rpmbuilder rpmbuilder 746256 4月 26 13:19 2016 haproxy-1.6.4-1.x86_64.rpm -rw-rw-r-- 1 rpmbuilder rpmbuilder 6916 4月 26 13:19 2016 haproxy-debuginfo-1.6.4-1.x86_64.rpm
出来たRPMをSelf Repositoryに登録してもよいし、直接 yum install haproxy-1.6.4-1.x86_64.rpm しても良い。
HAProxy の設定
HAProxyの設定ファイルはこんな感じ。ポイントは以下。
- v1.6の resolvers オプションを使ってVPCのnameserverを参照するようにし、A Recordの変更に追従させる。
- option mysql-check を指定して、 MySQL 層での Healthcheckを行う。
- backup に RDS Masterのendpointを指定し、Read Replica全滅時はMasterに向けるようにする
rsyslogの設定
HAProxyはsyslogでログを飛ばす。上の設定ファイルでは local2 に飛ばしているので、syslog / rsyslog の設定もあわせて変更する必要がある。 local2 を他の用途で使っている場合は、よしなに変更して下さい。以下、rsyslogの設定例。
$ sudo cp -p /etc/rsyslog.conf{,.bk}
$ sudo vim /etc/rsyslog.conf
$ diff -u /etc/rsyslog.conf{.bk,}
--- /etc/rsyslog.conf.bk 2014-12-10 19:05:22.000000000 +0900
+++ /etc/rsyslog.conf 2016-04-28 13:30:55.150168043 +0900
@@ -10,8 +10,8 @@
#$ModLoad immark # provides --MARK-- message capability
# Provides UDP syslog reception
-#$ModLoad imudp
-#$UDPServerRun 514
+$ModLoad imudp
+$UDPServerRun 514
# Provides TCP syslog reception
#$ModLoad imtcp
@@ -59,6 +59,9 @@
# Save boot messages also to boot.log
local7.* /var/log/boot.log
+local2.* -/var/log/haproxy.log
+#local2.warn -/var/log/haproxy.log
# ### begin forwarding rule ###
$ sudo /etc/init.d/rsyslog restart
監視用ユーザの追加
HAProxyの設定で、option mysql-check を指定しているが、これは MySQL 層での Healthcheckを行うためのもの。 このhealthcheckで使用するユーザをMySQLに用意してあげる。接続さえ出来れば良いので、最低限の権限で良い。
$ mysql -u rdsuser -h master.XXXXXXXXXXXX.ap-northeast-1.rds.amazonaws.com -p ... mysql> grant usage on *.* to 'haproxy'@'%'; mysql> flush privileges;
ここまで来たら、HAProxyを起動する。
$ sudo /etc/init.d/haproxy start
socat インストール
あと、HAProxyのステータス確認用のsocatをインストールしておく。 設定ファイルで指定したUNIX fileに対して標準入力でコマンド投げることでステータスの確認が可能。
$ yum install socat --enablrepo=epel
show stat コマンドでステータス確認できる。
$ echo "show stat" | sudo socat stdio /var/lib/haproxy/stats # pxname,svname,qcur,qmax,scur,smax,slim,stot,bin,bout,dreq,dresp,ereq,econ,eresp,wretr,wredis,status,weight,act,bck,chkfail,chkdown,lastchg,downtime,qlimit,pid,iid,sid,throttle,lbtot,tracked,type,rate,rate_lim,rate_max,check_status,check_code,check_duration,hrsp_1xx,hrsp_2xx,hrsp_3xx,hrsp_4xx,hrsp_5xx,hrsp_other,hanafail,req_rate,req_rate_max,req_tot,cli_abrt,srv_abrt,comp_in,comp_out,comp_byp,comp_rsp,lastsess,last_chk,last_agt,qtime,ctime,rtime,ttime, mysql,FRONTEND,,,0,0,512,0,0,0,0,0,0,,,,,OPEN,,,,,,,,,1,2,0,,,,0,0,0,0,,,,,,,,,,,0,0,0,,,0,0,0,0,,,,,,,, mysql,read01,0,0,0,0,,0,0,0,,0,,0,0,0,0,UP,1,1,0,0,0,4512,0,,1,2,1,,0,,2,0,,0,L7OK,0,4,,,,,,,0,,,,0,0,,,,,-1,5.6.19,,0,0,0,0, mysql,read02,0,0,0,0,,0,0,0,,0,,0,0,0,0,UP,1,1,0,0,0,4512,0,,1,2,2,,0,,2,0,,0,L7OK,0,1,,,,,,,0,,,,0,0,,,,,-1,5.6.19,,0,0,0,0, mysql,master,0,0,0,0,,0,0,0,,0,,0,0,0,0,UP,1,0,1,0,0,4512,0,,1,2,3,,0,,2,0,,0,L7OK,0,1,,,,,,,0,,,,0,0,,,,,-1,5.6.19-log,,0,0,0,0, mysql,BACKEND,0,0,0,0,52,0,0,0,0,0,,0,0,0,0,UP,2,2,1,,0,4512,0,,1,2,0,,0,,1,0,,0,,,,,,,,,,,,,,0,0,0,0,0,0,-1,,,0,0,0,0,
HAProxy経由でRead Replicaに接続してみる
今回の例ではRead Replicaは2台用意しており、round-robinされます。
$ mysql -u 127.0.0.1 -P 3306 -u recx -e "show variables like '%hostname%';" +---------------+---------------+ | Variable_name | Value | +---------------+---------------+ | hostname | ip-10-7-0-205 | +---------------+---------------+ $ mysql -u 127.0.0.1 -P 3306 -u recx -e "show variables like '%hostname%';" +---------------+--------------+ | Variable_name | Value | +---------------+--------------+ | hostname | ip-10-7-1-66 | +---------------+-------------- $ mysql -u 127.0.0.1 -P 3306 -u recx -e "show variables like '%hostname%';" +---------------+---------------+ | Variable_name | Value | +---------------+---------------+ | hostname | ip-10-7-0-205 | +---------------+---------------+
Read Replicaなので当然read-onlyが有効化されており、更新操作は出来ません。
$ mysql -u 127.0.0.1 -P 3306 -u recx -e "create database cannot_write;" ERROR 1290 (HY000) at line 1: The MySQL server is running with the --read-only option so it cannot execute this statement
localhost:3306 に繋げば自動的にReadReplicaに刺さることになるので、負荷分散以外にも日頃の運用で重宝する。
v1.6 のresolvers オプションの検証
期待通り A Record の変更に追従してくれるのか確認しておく。
まずは、HAproxyのバージョンが1.6であることを確認。
$ haproxy -v HA-Proxy version 1.6.4 2016/03/13 Copyright 2000-2016 Willy Tarreau <willy@haproxy.org>
続いてRDS の内部IP を変更する。 RDSのNodeのIP変更が発生する操作を実施すれば良い。今回はRead Replica (read01) の InstanceType の変更を実施してみる。 InstanceType変更操作を実施すると、以下のようにHAProxy上でDOWNステータスに変わったことを確認。
$ echo "show stat" | sudo socat stdio /var/lib/haproxy/stats # pxname,svname,qcur,qmax,scur,smax,slim,stot,bin,bout,dreq,dresp,ereq,econ,eresp,wretr,wredis,status,weight,act,bck,chkfail,chkdown,lastchg,downtime,qlimit,pid,iid,sid,throttle,lbtot,tracked,type,rate,rate_lim,rate_max,check_status,check_code,check_duration,hrsp_1xx,hrsp_2xx,hrsp_3xx,hrsp_4xx,hrsp_5xx,hrsp_other,hanafail,req_rate,req_rate_max,req_tot,cli_abrt,srv_abrt,comp_in,comp_out,comp_byp,comp_rsp,lastsess,last_chk,last_agt,qtime,ctime,rtime,ttime, mysql,FRONTEND,,,0,1,512,105,95066,538297,0,0,0,,,,,OPEN,,,,,,,,,1,2,0,,,,0,0,0,2,,,,,,,,,,,0,0,0,,,0,0,0,0,,,,,,,, mysql,read01,0,0,0,1,,16,3228,4932,,0,,1,0,3,0,DOWN,1,1,0,5,1,398,398,,1,2,1,,13,,2,0,,1,L4TOUT,,2001,,,,,,,0,,,,0,0,,,,,398,,,0,0,0,1, mysql,read02,0,0,0,1,,92,91838,533365,,0,,0,0,0,0,UP,1,1,0,0,0,501,0,,1,2,2,,92,,2,0,,1,L7OK,0,4,,,,,,,0,,,,0,0,,,,,6,5.6.19-log,,0,1,0,5, mysql,master,0,0,0,0,,0,0,0,,0,,0,0,0,0,UP,1,0,1,0,0,501,0,,1,2,3,,0,,2,0,,0,L7OK,0,0,,,,,,,0,,,,0,0,,,,,-1,5.6.19-log,,0,0,0,0, mysql,BACKEND,0,0,0,1,52,105,95066,538297,0,0,,1,0,3,0,UP,1,1,1,,0,501,0,,1,2,0,,105,,1,0,,2,,,,,,,,,,,,,,0,0,0,0,0,0,6,,,0,1,0,6,
しばらくするとRead ReplicaのInstanceType変更が終わり、それに伴いHAProxy上のread01のステータスもOKに戻ったことが確認できた。
$ echo "show stat" |sudo socat stdio /var/lib/haproxy/stats # pxname,svname,qcur,qmax,scur,smax,slim,stot,bin,bout,dreq,dresp,ereq,econ,eresp,wretr,wredis,status,weight,act,bck,chkfail,chkdown,lastchg,downtime,qlimit,pid,iid,sid,throttle,lbtot,tracked,type,rate,rate_lim,rate_max,check_status,check_code,check_duration,hrsp_1xx,hrsp_2xx,hrsp_3xx,hrsp_4xx,hrsp_5xx,hrsp_other,hanafail,req_rate,req_rate_max,req_tot,cli_abrt,srv_abrt,comp_in,comp_out,comp_byp,comp_rsp,lastsess,last_chk,last_agt,qtime,ctime,rtime,ttime, mysql,FRONTEND,,,0,0,512,0,0,0,0,0,0,,,,,OPEN,,,,,,,,,1,2,0,,,,0,0,0,0,,,,,,,,,,,0,0,0,,,0,0,0,0,,,,,,,, mysql,read01,0,0,0,0,,0,0,0,,0,,0,0,0,0,UP,1,1,0,8,1,447,191,,1,2,1,,0,,2,0,,0,L7OK,0,4,,,,,,,0,,,,0,0,,,,,-1,5.6.19-log,,0,0,0,0, mysql,read02,0,0,0,0,,0,0,0,,0,,0,0,0,0,UP,1,1,0,0,0,876,0,,1,2,2,,0,,2,0,,0,L7OK,0,0,,,,,,,0,,,,0,0,,,,,-1,5.6.19-log,,0,0,0,0, mysql,master,0,0,0,0,,0,0,0,,0,,0,0,0,0,UP,1,0,1,0,0,876,0,,1,2,3,,0,,2,0,,0,L7OK,0,4,,,,,,,0,,,,0,0,,,,,-1,5.6.19-log,,0,0,0,0, mysql,BACKEND,0,0,0,0,52,0,0,0,0,0,,0,0,0,0,UP,2,2,1,,0,876,0,,1,2,0,,0,,1,0,,0,,,,,,,,,,,,,,0,0,0,0,0,0,-1,,,0,0,0,0,
HAProxyのログには、IP変更の検知と、監視成功による切り戻しのログが出力される。
Apr 26 13:51:21 localhost haproxy[22217]: Server mysql/read01 is DOWN, reason: Layer4 connection problem, info: "Connection refused", check duration: 2ms. 1 active and 1 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. Apr 26 13:53:42 localhost haproxy[22217]: mysql/read01 changed its IP from 172.31.38.198 to 172.31.35.59 by awsvpc/vpc. Apr 26 13:54:32 localhost haproxy[22217]: Server mysql/read01 is UP, reason: Layer7 check passed, code: 0, info: "5.6.19", check duration: 4ms. 2 active and 1 backup servers online. 0 sessions requeued, 0 total in queue.
終わりに
MariaDBのJDBC Driverを使っても同要件を実現可能だが、実装コストが少なく言語問わず実現できるのでオススメ。 HAProxy自体は汎用的なL7 Balancerなので、何か課題に直面した時の選択肢として抑えておくと良いと思う。
Read Replicaのバランシングに関しては、Read Replica自体や、ELBがEC2以外のサービスに対応してくれる、みたいなリリースが出てくれるといいんだけどなぁ。

Amazon Web Services クラウドデザインパターン設計ガイド 改訂版
- 作者: 玉川憲,片山暁雄,鈴木宏康,野上忍,瀬戸島敏宏,坂西隆之,日経SYSTEMS
- 出版社/メーカー: 日経BP社
- 発売日: 2015/05/28
- メディア: 単行本
- この商品を含むブログ (3件) を見る
")
Amazon Web Services実践入門 (WEB+DB PRESS plus)
- 作者: 舘岡守,今井智明,永淵恭子,間瀬哲也,三浦悟,柳瀬任章
- 出版社/メーカー: 技術評論社
- 発売日: 2015/11/10
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
HAProxyのSPEC
Tarball は公式の HAProxy-1.6.4 から取得して下さい。 SPECにはTarballに含まれていないファイルのインストールも含まれているので、よしなにTarball固め直すなりSPEC編集して使って下さい。
参考
glibc 脆弱性対応に関する備忘録 (CVE-2015-7547)
※WebやSNSの情報漁った個人まとめなので、CVEやGoogleやRedhatなど各社が出している公式情報を参照してください。
CVE-2015-7547の内容
悲報。glibc 2.9以降の脆弱性が本日 2/17 (日本時間) 発見された。getaddinfo() 関数の脆弱性で悪用されるとリモートコードの実行が可能なリスクを孕んでいるとのこと。
「glibc」ライブラリに脆弱性、Linuxの大部分に深刻な影響 - ITmedia エンタープライズ Google Online Security Blog: CVE-2015-7547: glibc getaddrinfo stack-based buffer overflow
The glibc DNS client side resolver is vulnerable to a stack-based buffer overflow when the getaddrinfo() library function is used. Software using this function may be exploited with attacker-controlled domain names, attacker-controlled DNS servers, or through a man-in-the-middle attack.
要するに、
- glibc (2.9 later) に脆弱性が見付かった
- glibcのDNS resolver をbuffer overflowさせることで攻撃者は任意のコードを実行可能
- 例えば、中間者攻撃介して不正ドメインに誘導され、攻撃者のドメイン名をcallされるような処理くらうと発火
- さっさとglibc updateしてOS再起動(もしくはglibc参照しているプロセス再起動)しましょう
DNSサーバ側での対応
getaddrinfo() 関数のバッファオーバーフローが発動する2,148バイト以上の場合に成立するらしい。 そのため、DNSサーバ側で対処するなら、単純にDNS response sizeをTCP/UDP 共に2,048 byteに制限すれば良い。 上記の情報が正しければ、Google DNSもAWS DNSも対処済みとのことなので、厳しければ再起動せずこの方法でも回避できるとのこと。
これに関して早速良記事。 何か起きてからでは遅いのでさっさとglibc上げるに越したことはなさそうだけど。
glibc使って外部通信行ってるLinuxサーバの対応
各Distributionのパッチが公開されてから、RedhatさんGoogleさん公式発表してくれた。なので、公開されているパッチ当てれば基本はOK。
GHOST対応時に、sshログインできなくなる事象があったらしいので、念のため開発/検証用のサーバで挙動確認してみたけど、特に異常なし。
GHOST脆弱性にyum update glibc、その後リブートする前に - Qiita
CentOS6.6の個人検証機は無事updateできたので、本番にも適宜展開していく。 (CentOS古くてお恥ずかしい...)
# cat /etc/redhat-release CentOS release 6.6 (Final) # rpm -qa glibc glibc-2.12-1.166.el6_7.7.x86_64
OSのPython古くて困ってる場合はpyenv入れたら便利だよ
成り行き
運用管理サーバに使ってるCentOS 6で、色々オペレーションをやってるが、ここでaws-cliを使いたい。 aws-cliがPython 2.6のサポートを打ち切っていたので、これを機にPython2.7にあげたい。
$ pip install awscli DEPRECATION: Python 2.6 is no longer supported by the Python core team, please upgrade your Python. A future version of pip will drop support for Python 2.6 The directory '/home/uorat/.cache/pip/http' or its parent directory is not owned by the current user and the cache has been disabled. Please check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. The directory '/home/uorat/.cache/pip' or its parent directory is not owned by the current user and caching wheels has been disabled. check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. Requirement already satisfied (use --upgrade to upgrade): awscli in /usr/lib/python2.6/site-packages Requirement already satisfied (use --upgrade to upgrade): botocore==1.0.0b1 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): bcdoc<0.16.0,>=0.15.0 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): colorama<=0.3.3,>=0.2.5 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): docutils>=0.10 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): rsa<=3.1.4,>=3.1.2 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): argparse>=1.1 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): jmespath==0.7.1 in /usr/lib/python2.6/site-packages (from botocore==1.0.0b1->awscli) Requirement already satisfied (use --upgrade to upgrade): python-dateutil<3.0.0,>=2.1 in /usr/lib/python2.6/site-packages (from botocore==1.0.0b1->awscli) Requirement already satisfied (use --upgrade to upgrade): ordereddict==1.1 in /usr/lib/python2.6/site-packages (from botocore==1.0.0b1->awscli) Requirement already satisfied (use --upgrade to upgrade): simplejson==3.3.0 in /usr/lib64/python2.6/site-packages (from botocore==1.0.0b1->awscli) Requirement already satisfied (use --upgrade to upgrade): six<2.0.0,>=1.8.0 in /usr/lib/python2.6/site-packages (from bcdoc<0.16.0,>=0.15.0->awscli) Requirement already satisfied (use --upgrade to upgrade): pyasn1>=0.1.3 in /usr/lib/python2.6/site-packages (from rsa<=3.1.4,>=3.1.2->awscli) /usr/lib/python2.6/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:315: SNIMissingWarning: An HTTPS request has been made, but the SNI (Subject Name Indication) extension to TLS is not available on this platform. This may cause the server to present an in correct TLS certificate, which can cause validation failures. For more information, see https://urllib3.readthedocs.org/en/latest/security.html#snimissingwarning. SNIMissingWarning /usr/lib/python2.6/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:120: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. For more in formation, see https://urllib3.readthedocs.org/en/latest/security.html#insecureplatformwarning. InsecurePlatformWarning $ python --version Python 2.6.6
ただ、Pythonは依存関係が多く、単純にバージョン上げるとシステム全体に波及しかねないので、怖い。 Rubyだとrbenvやrvm, Node.jsだとnvm, 最近はこういうパッケージ管理/バージョン管理ツールが充実しており、Pytyonにも pyenv なるものがあることを知ったので、aws-cli使うときはこいつを利用しようという背景。
yyuu/pyenv https://github.com/yyuu/pyenv
pyenvインストール
とってもお手軽。 git cloneして、基本的にはpath通すだけ。
### git cloneしてくる $ git clone https://github.com/yyuu/pyenv.git ~/.pyenv Initialized empty Git repository in /home/uorat/.pyenv/.git/ remote: Counting objects: 11999, done. remote: Compressing objects: 100% (5/5), done. remote: Total 11999 (delta 0), reused 0 (delta 0), pack-reused 11994 Receiving objects: 100% (11999/11999), 2.12 MiB | 941 KiB/s, done. Resolving deltas: 100% (8334/8334), done. ### .bashrc/.bash_profile や .zshrc などに必要な変数や処理を追加 # echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile # echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile # echo 'eval "$(pyenv init -)"' >> ~/.bash_profile ### シェル再起動 (source ~/.bash_profile でも可) exec $SHELL -l ### 起動確認 $ pyenv help Usage: pyenv <command> [<args>] Some useful pyenv commands are: commands List all available pyenv commands local Set or show the local application-specific Python version global Set or show the global Python version shell Set or show the shell-specific Python version install Install a Python version using python-build uninstall Uninstall a specific Python version rehash Rehash pyenv shims (run this after installing executables) version Show the current Python version and its origin versions List all Python versions available to pyenv which Display the full path to an executable whence List all Python versions that contain the given executable See `pyenv help <command>' for information on a specific command. For full documentation, see: https://github.com/yyuu/pyenv#readme
使い方
思想は rbenv と一緒。
python入れるときは pyenv install -l でインストール可能なバージョンを探して、installする。
pypyやjythonも入れられる。
$ pyenv install -l Available versions: 2.1.3 2.2.3 ... 2.7.9 2.7.10 2.7.11 ... 3.5-dev 3.5.1 3.6-dev ... anaconda3-2.4.0 anaconda3-2.4.1 ... jython-2.7.0 jython-2.7.1b1 jython-2.7.1b2 ... pypy3-2.3.1-src pypy3-2.3.1 pypy3-2.4.0-src pypy3-2.4.0 ... stackless-3.3.5 stackless-3.4.1 ...
python 2.7.11をpyenvで入れてみる。コンパイル走り負荷上がるので少しだけ注意。
$ pyenv install 2.7.11 Downloading Python-2.7.11.tgz... -> https://www.python.org/ftp/python/2.7.11/Python-2.7.11.tgz Installing Python-2.7.11... WARNING: The Python readline extension was not compiled. Missing the GNU readline lib? WARNING: The Python bz2 extension was not compiled. Missing the bzip2 lib? WARNING: The Python sqlite3 extension was not compiled. Missing the SQLite3 lib? Installed Python-2.7.11 to /home/uorat/.pyenv/versions/2.7.11 ### 入ったことを確認。 $ pyenv versions * system (set by /home/uorat/.pyenv/version) 2.7.11
pyenvで使用するPythonを切り替える。この辺りの使い勝手もrbenvと一緒。
### 現在のバージョン確認。最初はsystemのPython 2.6を見ている。 $ pyenv version system (set by /home/uorat/.pyenv/version) ### 切り替える $ pyenv global 2.7.11 ### 確認 $ pyenv version 2.7.11 (set by /home/uorat/.pyenv/version) $ pyenv versions system * 2.7.11 (set by /home/uorat/.pyenv/version) $ python --version Python 2.7.11 $ which python /home/uorat/.pyenv/shims/python
pyenv下でaws-cli入れてみる
無事Python 2.7が入ったのでaws-cli 入るか試してみる。
$ pip install awscli
The directory '/home/uorat/.cache/pip/http' or its parent directory is not owned by the current user and the cache has been disabled. Please check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag.
The directory '/home/uorat/.cache/pip' or its parent directory is not owned by the current user and caching wheels has been disabled. check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag.
Collecting awscli
Downloading awscli-1.10.1-py2.py3-none-any.whl (880kB)
100% |████████████████████████████████| 884kB 595kB/s
Collecting botocore==1.3.23 (from awscli)
Downloading botocore-1.3.23-py2.py3-none-any.whl (2.2MB)
100% |████████████████████████████████| 2.2MB 237kB/s
Collecting rsa<=3.3.0,>=3.1.2 (from awscli)
Downloading rsa-3.3-py2.py3-none-any.whl (44kB)
100% |████████████████████████████████| 45kB 2.7MB/s
Collecting colorama<=0.3.3,>=0.2.5 (from awscli)
Downloading colorama-0.3.3.tar.gz
Collecting docutils>=0.10 (from awscli)
Downloading docutils-0.12.tar.gz (1.6MB)
100% |████████████████████████████████| 1.6MB 320kB/s
Collecting jmespath<1.0.0,>=0.7.1 (from botocore==1.3.23->awscli)
Downloading jmespath-0.9.0-py2.py3-none-any.whl
Collecting python-dateutil<3.0.0,>=2.1 (from botocore==1.3.23->awscli)
Downloading python_dateutil-2.4.2-py2.py3-none-any.whl (188kB)
100% |████████████████████████████████| 192kB 2.4MB/s
Collecting pyasn1>=0.1.3 (from rsa<=3.3.0,>=3.1.2->awscli)
Downloading pyasn1-0.1.9-py2.py3-none-any.whl
Collecting six>=1.5 (from python-dateutil<3.0.0,>=2.1->botocore==1.3.23->awscli)
Downloading six-1.10.0-py2.py3-none-any.whl
Installing collected packages: jmespath, six, python-dateutil, docutils, botocore, pyasn1, rsa, colorama, awscli
Running setup.py install for docutils ... done
Running setup.py install for colorama ... done
Successfully installed awscli-1.10.1 botocore-1.3.23 colorama-0.3.3 docutils-0.12 jmespath-0.9.0 pyasn1-0.1.9 python-dateutil-2.4.2 rsa-3.3 six-1.10.0
成功! あとは、いつもどおりaws configureして、使えば良い。
$ aws configure --profile=hogehoge AWS Access Key ID [None]: AKIA******************* AWS Secret Access Key [None]: ************************************** Default region name [None]: ap-northeast-1 Default output format [None]: $ aws s3 ls --profile=hogehoge 2016-02-02 13:07:03 hogehoge-bucket
aws-cliやAnsibleなどPython系のツールを使いたいけどPythonのバージョンがfdksajfjdsak; 的な悩みを抱えてる方はpyenv使いましょう。
MHAを使ってZabbixをカジュアルに冗長化してみる
Onpremiseな環境でHAなDBクラスタを組んだり監視サーバを構築したりなんて作業は、ちょっと前であればごくごく当たり前のものだったけど、最近はクラウドやSaas/Paasをどれだけ活用して、よりビジネスの本流に集中しようというご時世。 でも、やっぱりOnpremise、どうしても必要な時はある。今のレールに頼り切るのもいいけど、やっぱり勘所はおさえておきたいので、カジュアルにZabbixをHAした時のことを備忘録しておきます。
やりたいこと
Zabbix serverを冗長構成にしたい。 Zabbix serverの稼働に必要なものはざっくり以下。
Zabbix serverをActive-Activeで稼働させてしまうと、データベースに二重で書き込みが行われてしまうので、Active-Standbyにしておく必要がある。障害時に手動切替なんて面倒、かつ二次障害起こしかねないので避けたい。MySQLもReplication組むだけでは弱いので自動フェイルオーバーくらいさせておきたい。そもそも監視サーバなので手間隙かけたくないし、むしろちょっとしたノード障害くらい放置しておきたい。
MySQLには5.6以降、GTID + failoverが標準搭載されているが、5.6出たばかりの時にGTIDのバグを幾つか踏んで痛い目にあったのと、上述の通りZabbix serverもまとめてHA化したいが幾つものクラスタウェア使って運用するのは腰が重い。カジュアルに一括りにしてよろしくやってほしい。
ということで、MHA。MySQLのReplicationのラグをよしなに埋めてくれる素敵なものにもかかわらず、挙動や構成が大変シンプル、拡張ポイントも多く、カジュアルにZabbixまで含めたクラスタウェアとして使えそうだったので採択決めました。
MHAいろは
MHAのアーキテクチャや仕組みは、詳しくは 公式ドキュメント を参照。要点をまとめるとMHA自体の責務は大きく以下。
- MySQLの監視
- Master/Slave ノードの監視
- Replicationステータス/各ノードのPOSチェック/遅延状況
- Binlog出力有無
- Read Only有無
- など
- Failover
- 故MasterからのBinlog救出
- 昇格候補の選出
- 新Masterへの差分データ適用
- 新MasterへのRead only無効化
- 他Slaveへの差分データ適用
- 他SlaveのMaster host切替 (
CHANGE MASTER)
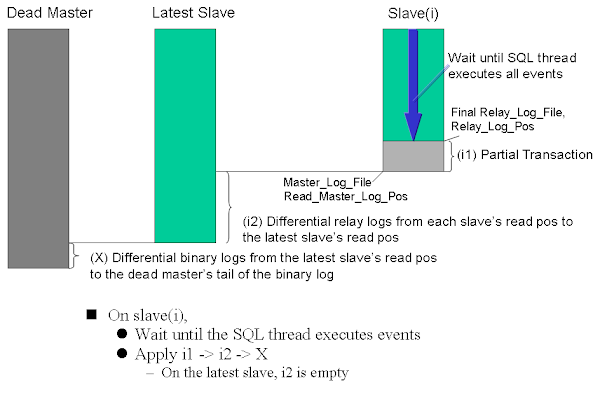
実システムでDBのSlaveを昇格させるには、これ以外に業務や環境に依存する様々な処理が必要になるが、MHAでは様々なフックポイントが用意されているので、適切な場所に拡張スクリプトを仕込めば、実システムにあわせたFailover作業を全自動で行うことができる。 拡張スクリプトはPerlスクリプトで実装する。MHAがPerlで実装されており、これが内部でcallされるため。詳しくはソースコード参照。
構成は、以下の図のとおり、MySQL監視プロセスとしてのMasterHA-Manager (masterha_managerプロセス) と、MySQL各サーバ上で動作するMasterHA-Nodeが必要となる。Managerは監視プロセスとなるため常駐させる必要がある。Nodeは、Failover時にManagerから適宜SSH経由で発行される幾つかのコマンドを処理するだけとなるので、MasterHA-Nodeの動作に必要なものをインストールしておくだけで良い。
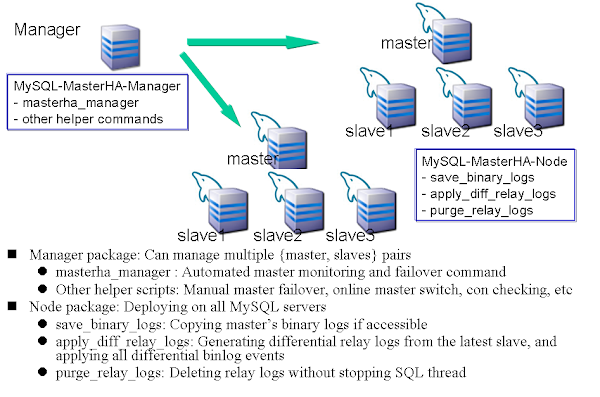 いずれも軽量なプロセスなので、好きなように構成組めば良い。例えばこんなところか。
いずれも軽量なプロセスなので、好きなように構成組めば良い。例えばこんなところか。
松: 昇格用slaveと参照用DBを分ける
MHA manager [192.168.10.1] Master [192.168.10.11, VIP: 192.168.10.10] ├── Slave (cadidate_master) [192.168.10.12] ├── Slave (no_master, Read only) [192.168.10.13] └── Slave (no_master, Read only) [192.168.10.14]
竹: Slave 1機, Manager用のノードは別筐体
MHA manager [192.168.10.1] Master [192.168.10.11, VIP: 192.168.10.10] └── Slave [192.168.10.12]
梅: 最小構成
Master [192.168.10.11, VIP: 192.168.10.10] └── Slave (w/ MHA manager) [192.168.10.12]
MHA自体は単体で動作し、あくまでクラスタの監視と、Failover時のリカバリとフックポイントを提供するのみなので、既に稼働中の環境でもねじ込める点も良い。非常に軽量な作りなので、新設/既設いずれも親和性が高いだろう。
MHAはRPMが公開されておりインストールは瞬殺で終わるので割愛。 Managerの他、MySQLが稼働している全サーバにMHA Nodeを入れる必要がある点に注意。 詳細は、Installation を参照。
MHAの拡張ポイント
MHAの設定ファイルで、以下のParameterを定義できる。Perlスクリプトのpathを記載することで、これらが呼び出されるようになる。 https://code.google.com/p/mysql-master-ha/wiki/Architecture#Custom_Extensions
代表的なものを紹介すると、
master_ip_failover_script
※詳しくは 公式ドキュメント を参照
Failover時の挙動を指定できる。代表的なものは、仮想IPの付け替え、クラスタウェアの再起動、アプリケーションの参照先DBの切替など。
以下の3地点で、これらの拡張Perlスクリプトがcallされる。 Failoverの瞬間だけ実行されるわけではない点に注意して実装すること。
MHA Manager calls master_ip_failover_script three times. First time is before entering master monitor (for script validity checking), second time is just before calling shutdown_script, and third time is after applying all relay logs to the new master. MHA Manager passes below arguments (you don't need to set these arguments in the config file).
要するに以下のタイミングで発火されるので、"command" パラメータで条件分岐するようなPerlスクリプトを仕込めば良い。その他、スクリプトに渡される引数もあわせて、以下に記載しておく。
- Checking phase : MHA-Manager起動時(--command=status)
- Current master shutdown phase : Masterサーバシャットダウン時(--command=stop or stopssh)
- New master activation phase : フェイルオーバー完了時(--command=start)
- --command=start
- --ssh_user=(new master's ssh username)
- --orig_master_host=(dead master's hostname)
- --orig_master_ip=(dead master's ip address)
- --orig_master_port=(dead master's port number)
- --new_master_host=(new master's hostname)
- --new_master_ip=(new master's ip address)
- --new_master_port(new master's port number)
- --new_master_user=(new master's user)
- --new_master_password(new master's password)
サンプルコードは以下 https://github.com/yoshinorim/mha4mysql-manager/blob/master/samples/scripts/master_ip_failover
shutdown_script
※詳しくは 公式ドキュメント を参照
オプションで指定するPerlスクリプトで、Failover後のshutdown処理を指定できる。Split brain防止のために使用する。例えば、IPMIやiDRAC, ilo経由, ESXi cli, その他Hypervisor経由の強制シャットダウン、電源OFFなど。 発火タイミングは、 master_ip_failover_script --command=stopssh|stop の直後。SSH reachableな場合とそうでない場合で挙動を変えられる。
サンプルコードは以下 https://github.com/yoshinorim/mha4mysql-manager/blob/master/samples/scripts/power_manager
例えば、ESXiの場合、vim-cmd で以下のようなコマンドを実行するイメージ。statusチェック, 電源OFF, 電源ONできるので、これを含むPerlスクリプトを仕込めば実現できる。
# VMID=`vim-cmd vmsvc/getallvms|grep zabbix-test01|awk '{print $1}'` && if [ -n "$VMID" ]; then vim-cmd vmsvc/power.getstate $VMID; fi
Retrieved runtime info
Powered on
# VMID=`vim-cmd vmsvc/getallvms|grep zabbix-test01|awk '{print $1}'` && if [ -n "$VMID" ]; then vim-cmd vmsvc/power.off $VMID; fi
Powering off VM:
# VMID=`vim-cmd vmsvc/getallvms|grep zabbix-test01|awk '{print $1}'` && if [ -n "$VMID" ]; then vim-cmd vmsvc/power.on $VMID; fi
Powering on VM:
MHA managerプロセスのバックグラウンド起動
普通に起動するとフォアグラウンド。公式ドキュメント はDaemonTools使っているが、Upstart等Linuxのサービス管理ツールでもシンプルに実現できるので、この辺りでデーモン化してあげると手軽で良いだろう。 MHA MnanagerプロセスはFailoverすると終了するライフサイクルになっているので、自動起動やrespawn処理はあまり入れないほうが良さそうな気がする。以下サンプル。
description "MasterHA manager services" chdir /var/log/masterha exec /usr/bin/masterha_manager --conf=/etc/mha.cnf >> /var/log/masterha/masterha_manager.log 2>&1 pre-start exec /usr/bin/masterha_check_repl --conf=/etc/mha.cnf post-stop exec /usr/bin/masterha_stop --conf=/etc/mha.cnf
起動/終了/ステータスチェックはこんな感じ。
- start masterha-manager
- status masterha-manager
- stop masterha-manager
MySQL インストール
詳細は割愛。 MySQL 5.6でも5.7でも動くぽいので、好きなモノを選べば良いと思う。 注意点は以下。
- MySQL
- MySQL 5.7の罠があなたを狙っている - Slideshare
- Semi Replicationは有効化
- Master - Slave間の欠損が限りなく0に近くなるので、Failoverが早くなる。
- ただし、レイテンシとのトレードオフで判断すること
- relay_log_info_repository=TABLE はやめておけ
- MHA利用時、これを入れていると以下のようなエラーが出た。relay_log情報はMHAがよろしく見てくれるので、my.cnfではあえて有効化しておく必要はなし。
Getting relay log directory or current relay logfile from replication table failed on
- relay_log_purge = 0
- read_only は set文で。my.cnfには書くな。
- 元のSlaveがMasterに昇格した時に、my.cnfに read_only = 1 がセットされていると再起動のタイミングで戻り障害を引き起こす可能性があるため危険。
Zabbix インストール
ようやくZabbix。インストールの詳細は例によって割愛。
ポイントは、冒頭で触れたとおりMHAでZabbixまで含めてクラスタ化するため、MySQLのMasterと同一サーバ上でZabbix serverを稼働させるようにすること。 Zabbix serverプロセスをPacemaker等、別の機構でクラスタ化しても良いのだが、実績上Zabbix serverプロセスが落ちる可能性よりもホストがポシャることの方が多かったので。監視サーバなので、という割り切りです。なので、設定は以下のような感じ。
- zabbix_server.conf
Zabbix web (Apache + PHP) は、複数Activeで動作可能ので上述のクラスタとはわけて考えて良い。 何人ものエンジニアが大量のグラフが貼られたスクリーンを定期リロードすることを考えると、むしろ別サーバにApache + PHP専用機並べてバランシングさせておきたいくらい。 なので、PHPからDBの接続はVIP経由でアクセスさせる。以下、Webの初期設定のポイントを列挙しておく。それぞれのWebサーバに対して設定行うこと。
- http://$HOSTNAME/zabbix/ にアクセス
- インストール画面が出てくるので進めていく
- DB接続情報は以下で入力
- Database Host: VIP
- Database User: zabbix
- Database Password: 設定したパスワード
- Test Connectionして接続確認
- Zabbix server Detailは以下で入力
- Host: VIP
- Name: 任意の名前 (環境が分かると良い)
- 確認ダイアログが出るので、間違いないか確認。
- これを全てのApache/PHPに対して行う (↑で生成された設定ファイル撒くでも構わない)
master_ip_failoverスクリプト for zabbix
最後の仕上げ。MHAで障害検知時は、MySQLの他、VIPとZabbix serverもセットでFailoverさせるようなスクリプトを用意しておく。あとは、/etc/mha.cnf の master_ip_failover に指定しておけば良い。 VIPの付け替えを行うのでARPキャッシュの更新を忘れないように。さもないと、フェイルオーバーしたのにつながらないなんてことのないように。 以下、サンプルです。
#!/usr/bin/env perl # # If you wanna know about the paramaster, "master_ip_failover_script", # read the below document. # # https://code.google.com/p/mysql-master-ha/wiki/Parameters#master_ip_failover_script # # [Usage] # master_ip_failover_zabbix \ # --virtual_ip=192.168.10.10/16 \ # --orig_master_vip_eth=eth0 \ # --new_master_vip_eth=eth0 # # [Description] # --virtual_ip => Virtual IP / mask # --orig_master_vip_eth => Device name that is attached virtual ip on origin master host. # --new_master_vip_eth => Device name that is attached virtual ip on new master host. # use strict; use warnings FATAL => 'all'; use Getopt::Long; use MHA::DBHelper; my ( $command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port, $new_master_user, $new_master_password, $virtual_ip, $orig_master_vip_eth, $new_master_vip_eth ); GetOptions( 'command=s' => \$command, 'ssh_user=s' => \$ssh_user, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, 'new_master_user=s' => \$new_master_user, 'new_master_password=s' => \$new_master_password, 'virtual_ip=s' => \$virtual_ip, 'orig_master_vip_eth=s' => \$orig_master_vip_eth, 'new_master_vip_eth=s' => \$new_master_vip_eth, ); exit &main(); sub main { # for debug print("---------- start master_ip_failover script ----------"); if ( defined $command ) { print(" command => $command\n") }; if ( defined $ssh_user ) { print(" ssh_user=s => $ssh_user\n") }; if ( defined $orig_master_host ) { print(" orig_master_host => $orig_master_host\n") }; if ( defined $orig_master_ip ) { print(" orig_master_ip => $orig_master_ip\n") }; if ( defined $orig_master_port ) { print(" orig_master_port => $orig_master_port\n") }; if ( defined $new_master_host ) { print(" new_master_host => $new_master_host\n") }; if ( defined $new_master_ip ) { print(" new_master_ip => $new_master_ip\n") }; if ( defined $new_master_port ) { print(" new_master_port => $new_master_port\n") }; if ( defined $virtual_ip ) { print(" virtual_ip => $virtual_ip\n") }; if ( defined $orig_master_vip_eth ) { print(" orig_master_vip_eth => $orig_master_vip_eth\n") }; if ( defined $new_master_vip_eth ) { print(" new_master_vip_eth => $new_master_vip_eth\n") }; # For current mastre shutdown phase # execute the below flow. # 1. unbind virtual ip from the origin master host. # 2. stop zabbix server process. if ( $command eq "stop" || $command eq "stopssh" ) { my $exit_code = 1; eval { `ssh $orig_master_host -o 'ConnectTimeout=5' '/etc/init.d/zabbix-server stop; /sbin/ip addr del $virtual_ip dev $orig_master_vip_eth'`; $exit_code = 0; }; if ($@) { warn "Got Error while shutdown phase: $@\n"; exit $exit_code; } exit $exit_code; } # For new master activation phase # execute the below flow. # 1. start zabbix server process. # 2. bind virtual ip on the new master host. # # Notice: # * You don't need to unable the paramster "read_only = 1" and enable binary log, # because they are already defined MHA common module. # elsif ( $command eq "start" ) { my $exit_code = 10; eval { my $ping_interface = join(".", $virtual_ip =~ /(\d+)\.(\d+)\.(\d+)\.(\d+)/ ); `ssh $new_master_host -o 'ConnectTimeout=15' '/sbin/ip addr add $virtual_ip dev $new_master_vip_eth && /sbin/arping -U $ping_interface -c 3 && /etc/init.d/zabbix-server start'`; $exit_code = 0; }; if ($@) { warn "Got Error while activation phase: $@\n"; # If you want to continue failover, exit 10. exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { # do nothing exit 0; } else { &usage(); exit 1; } } sub usage { print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port --virtual_ip=ip --orig_master_vip_eth=eth --new_master_vip_eth=eth\n"; }
以上で、カジュアルにZabbix serverが冗長化出来ます。 Zabbix serverプロセスが落ちたりVIP剥がれてもFailoverしないので、そのあたりは割りきって参考にして下さい。
まとめ
MHAはソースもPerlでそこまでボリューム多くないので気軽に読めちゃいます。 日本語の情報も多い(なにせ作者が日本人: 元DeNA, 現Facebookの松信さん)ので、他メンバーへの技術トランスファーも楽ちん、運用容易性が非常に高いのでおすすめです。
結局、MHAの宣伝みたいになってしまいました。。